I recently looked at using pjeziorowski’s rollout tool to cross-publish to hashnode and devto. Started making a few minor changes. Then considered a few contentious changes. And in the end decided I should just make my own in Rust. Because… Rust in all the things.
I settled on the following requirements:
-
Post multiple places
I’ve been using GitHub Pages and cross-posting to devto via RSS feed. But this tends to munge articles a bit; strips syntax highlighting, adds a linefeed to end of code blocks, mangles links to other articles, etc. All this requires manual fixing before publishing, so I’ve never been happy with it.
-
Keep articles up to date
POSTing is one thing, but I regularly make updates/corrections that I’d like to propogate. Pretty much all my devto articles are out of date, for this I needPUT. -
Manage
canonical_url(and front matter, in general)Based on where/when the original is posted set the canonical URL for the cross-posts.
-
Async
I’m impatient. But I also anticipate needing to do a few requests to publish and update articles.
-
Markdown
Articles are written in markdown and may contain Jekyll front-matter as used by Github Pages.
To avoid confusion with the original (or some Ruby feature flag thingie), I dub thee… BULLHORN (stylized in all-caps, for obvious reasons). Rough code is on Github
Devto and REST
The devto API is pretty straight-forward.
“How to choose the right Rust HTTP client” gives a good overview of Rust HTTP crates. In this case, I settled on reqwest.
// Helper state
pub struct DevtoCrossPublish<'s> {
settings: &'s Settings,
api_token: String,
client: reqwest::Client,
}
// Serialized to JSON and used as body of HTTP request
#[derive(serde::Serialize)]
struct Article {
title: String,
body_markdown: String,
published: bool,
canonical_url: Option<String>,
#[serde(skip_serializing_if = "Vec::is_empty")]
tags: Vec<String>,
series: Option<String>,
}
// API is expecting:
// {
// article: {
// title: ...
// body_markdown: ...
// }
// }
#[derive(serde::Serialize)]
struct Body {
article: Article,
}
Posting a new article is pretty simple:
let body = Body {
article: //...
};
self.client.post("https://dev.to/api/articles")
// Authenticate
.header("api-key", &self.api_token)
.json(&body)
.send()
.await
Updating an article takes a bit more. Need to find the devto article corresponding to the original. I decided the canonical URL was the best way to do this because once published it shouldn’t change.
// Get page of most recent articles
let me_articles = self.client.get("https://dev.to/api/articles/me")
.header("api-key", &self.api_token)
.send()
.await;
// Find article with matching canonical URL, if it exists
let compare_val = &post.front_matter.canonical_url;
let existing_id = if let Ok(me_articles) = me_articles {
let me_articles = me_articles.json::<Vec<ArticleResponse>>().await?;
me_articles.iter()
.find(|a| self.compare(a, &compare_val))
.and_then(|x| Some(x.clone()))
} else {
None
}
// Note `put` and URL for existing article
self.client.put(format!("https://dev.to/api/articles/{}", existing_id))
.header("api-key", &self.api_token)
.json(&body)
.send()
.await
Medium and REST
The medium API is pretty limited. You can post new articles, but you can’t update (i.e. PUT) existing articles. In fact, you can’t even GET your articles. Regardless, I’d still like to check for an article using the canonical URL to avoid POSTing a duplicate. Unfortunately, it seems the only viable option to obtain your articles is to get your RSS feed, get individual posts, and check the HTML <head> element for the canonical link.
Based on this article, I decided to try quick-xml. In Cargo.toml:
[dependencies]
quick-xml = { version = "0.22", optional = true }
rss = { version = "1.10", optional = true }
Next:
// Get RSS feed
let feed = self.client.get(format!("https://medium.com/feed/@{}", user.username))
.send()
.await?
.bytes()
.await?;
// Parse RSS feed
let channel = rss::Channel::read_from(&feed[..])?;
// Iterate over links to posts
for item in channel.items {
if let Some(link) = item.link {
// Get article
let story = self.client.get(link)
.send().await?
.text().await?;
// Extract canonical `<link>` from `<head>`
// ...
}
}
When you get an article, the response body contains:
<!-- SNIP -->
<head>
<!-- SNIP -->
<link data-rh="true" rel="canonical"
href="https://rendered-obsolete.github.io/2021/05/03/dotnet_calli.html" />
<link data-rh="true" rel="alternate" href="..." />
<script data-rh="true" type="application/ld+json">...</script>
<link rel="preload" href="..." as="script">
<style type="text/css" data-fela-rehydration="456" data-fela-type="STATIC">
<!-- SNIP -->
</head>
<!-- SNIP -->
You can see the canonical URL with rel="canonical". In theory we should be able to enable the "serialize" feature of quick-xml and follow the example to decode with:
#[derive(Debug, serde::Deserialize, PartialEq)]
struct Html {
head: Head,
}
#[derive(Debug, serde::Deserialize, PartialEq)]
struct Head {
title: String,
links: Vec<Workaround>,
}
#[derive(Debug, serde::Deserialize, PartialEq)]
#[serde(rename_all = "lowercase")]
enum Workaround {
Link(Link),
Script,
}
#[derive(Debug, serde::Deserialize, PartialEq)]
struct Link {
rel: String,
href: String,
sizes: Option<String>,
}
let story: Html = quick_xml::de::from_str(&story)?;
enum Workaround is needed because serde doesn’t like the <script> mixed in between <link>s (see this issue). However, it fails with EndEventMismatch { expected: "link", found: "head" }. If you look at the last <link> in the response it’s never closed with />- HTML isn’t necessarily valid XML. So we’ll instead need to follow the reader example and manually traverse the HTML:
let mut reader = quick_xml::Reader::from_str(xml);
reader.trim_text(true);
let mut buf = Vec::new();
let mut is_head = false;
loop {
use quick_xml::events::{Event, BytesEnd, BytesStart};
match reader.read_event(&mut buf) {
Ok(Event::Start(ref e)) if e.name() == b"head" => {
is_head = true;
},
Ok(Event::End(ref e)) if is_head && e.name() == b"head" => {
is_head = false;
break;
},
Ok(Event::Empty(ref e)) if is_head && e.name() == b"link" => {
// Check `e.attributes()` key/value for `rel="canonical"`, etc.
},
Ok(Event::Eof) => break,
}
buf.clear();
}
Posting an article is similar to devto:
let resp = self.client.post(format!("{}/users/{}/posts", URL, user.id))
.header("Authorization", format!("Bearer {}", self.api_token))
.json(&body)
.send()
.await?;
Hashnode and GraphQL
Hashnode provides a GraphQL API. A GraphQL tutorial is out of scope, but I’ll cover the basics. https://graphql.org/learn/ is a good place for further information.
Hashnode has a web-based API sandbox, but the VSCode extension is even comfier because you can test your queries and then use them directly in Rust:
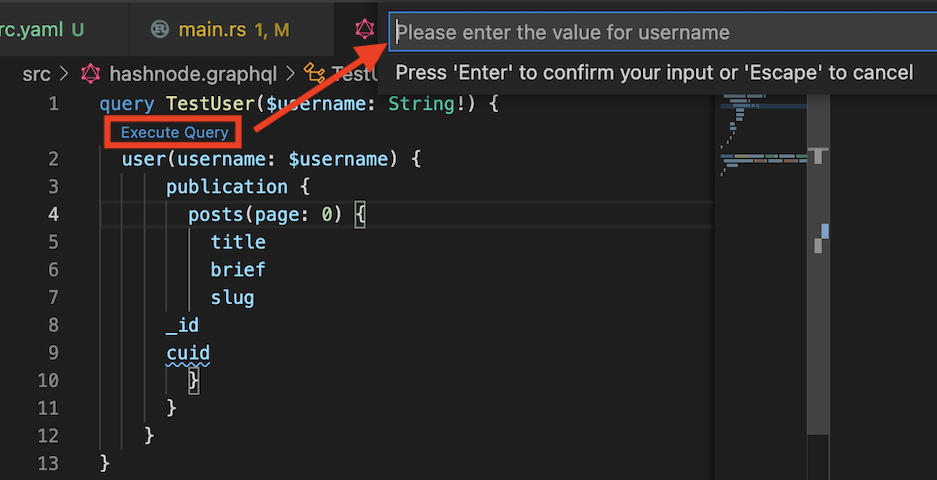
Populate .graphqlrc.yaml with:
schema: https://api.hashnode.com/
extensions:
endpoints:
default:
url: https://api.hashnode.com/
headers:
Authorization: ${HASHNODE_API_TOKEN}
The will give requests made by the VSCode extension an Authorization header based on HASHNODE_API_TOKEN environment variable.
Create src/hashnode.graphql:
# `query` keyword and the name we'll use in client code
query Tags {
# The query we'll run
tagCategories {
# Fields to include in response
_id
name
slug
}
}
Click Execute Query in VSCode and it should output:
{
"data": {
"tagCategories": [
{
"_id": "56744721958ef13879b94cad",
"name": "JavaScript",
"slug": "javascript"
},
...
Note the fields in the response match what we requested.
The main Rust code-first GraphQL project seems to be Juniper. Seeing as how I can’t abide code littered with string liter-als (pun intended), the schema-first options boil down to juniper-from-schema and graphql-client. I started with the latter mainly because it has far more stars on github and downloads on crates.io, but also because their examples use reqwest.
To use in Rust:
# Download `graphql-client` tool to `~/.cargo/bin/` (add to $PATH)
cargo install graphql_client_cli
# Get hashnode API schema
graphql-client introspect-schema --output hashnode_schema.json https://api.hashnode.com/
Time for macro magic:
#[derive(graphql_client::GraphQLQuery)]
#[graphql(
schema_path = "hashnode_schema.json",
query_path = "src/hashnode.graphql",
// Added to `#[derive()]` on `ResponseData`
response_derives = "Debug"
)]
// Name matches query in hashnode.graphql
pub struct Tags;
let body = Tags::build_query(tags::Variables);
// Post query to hashnode server
let resp = self.client.post("https://api.hashnode.com/")
.json(&body)
.send()
.await?;
// Response is GraphQL `[Tags]` type (array itself and contained items can be null).
// But, `[Tags!]!` (nothing is null) is easier to deal with in Rust
let categories: Vec<tags::TagsTagCategories> = {
// Make sure to wrap your `ResponseData` with `graphql_client::Response`!
// If you `resp.json<test::ResponseData>()` you'll get nothing because the
// response is `{ data: ResponseData }`
let categories: graphql_client::Response<tags::ResponseData> = resp.json().await?;
categories.data
.and_then(|d| d.tag_categories)
// Turn `Option<Vec<Option<_>>>` into `Vec<_>`
.unwrap_or_default()
.into_iter()
.flatten()
.collect()
};
That probably looks like a lot of code and types. Rust can infer many of the types and I could have imported the namespaces, but I find it helpful to see explicit modules and types until you understand what’s going on. The last third is just collapsing Option<>/None.
If you want to see what the #[derive()] and #[graphql()] macros are doing behind the scenes, you can explicitly generate Rust source:
graphql-client generate src/hashnode.graphql --output-directory src --schema-path ./hashnode_schema.json
hashnode.rs contains the generated code:
pub struct Tags;
pub mod tags {
#![allow(dead_code)]
pub const OPERATION_NAME: &'static str = "Tags";
pub const QUERY : & 'static str = "query Tags {\n tagCategories{\n _id\n name\n slug\n }\n}" ;
use serde::{Deserialize, Serialize};
#[allow(dead_code)]
type Boolean = bool;
#[allow(dead_code)]
type Float = f64;
#[allow(dead_code)]
type Int = i64;
#[allow(dead_code)]
type ID = String;
#[derive(Deserialize)]
pub struct TagsTagCategories {
#[serde(rename = "_id")]
pub id: ID,
pub name: String,
pub slug: String,
}
#[derive(Serialize)]
pub struct Variables;
#[derive(Deserialize)]
pub struct ResponseData {
#[serde(rename = "tagCategories")]
pub tag_categories: Option<Vec<Option<TagsTagCategories>>>,
}
}
impl graphql_client::GraphQLQuery for Tags {
type Variables = tags::Variables;
type ResponseData = tags::ResponseData;
fn build_query(variables: Self::Variables) -> ::graphql_client::QueryBody<Self::Variables> {
graphql_client::QueryBody {
variables,
query: tags::QUERY,
operation_name: tags::OPERATION_NAME,
}
}
}
Main take-aways:
- You end up using both
tags::andTags::(note capitalT) - serde is used for serialization to/from JSON
- The nullable GraphQL type
TYPEbecomesOption<TYPE>in Rust, while the non-nullable GraphQLTYPE!becomesTYPE
Posting an article can be done with a “mutation”. This example is interesting because it shows how to pass arguments to GraphQL with Variables. In hashnode.graphql add:
# We'll provide `$input` and `$pubId` arguments in Rust
mutation CreatePubStory($input: CreateStoryInput!, $pubId: String!, $hideFromFeed: Boolean = false) {
# This is the mutation, we use arguments from above
createPublicationStory(input: $input, publicationId: $pubId, hideFromHashnodeFeed: $hideFromFeed) {
# Response fields specified in fragment
...createResponseFields
}
}
# Fragment usable on CreatePostOutput types
fragment createResponseFields on CreatePostOutput {
code
success
message
}
And the corresponding Rust is similar to before:
#[derive(graphql_client::GraphQLQuery)]
#[graphql(
schema_path = "hashnode_schema.json",
query_path = "src/hashnode.graphql",
response_derives = "Debug",
// Add `#[derive(Default)]` to `Variables` type
variables_derives = "Default"
)]
pub struct CreatePubStory;
// Struct used as mutation input
let input = create_pub_story::CreateStoryInput {
content_markdown: post.body,
tags, // Tags from earlier query
title: post.front_matter.title,
// etc...
};
// Pass `$input` and `$pub_id` arguments to `CreatePubStory` mutation in hashnode.graphql via `Variables` struct
let body = CreatePubStory::build_query(create_pub_story::Variables {
input,
pub_id: self.pub_id.clone(),
..Default::default() // Since we added #[derive(Default)]
});
let resp = self.client.post("https://api.hashnode.com/")
// Required authorization header
.header("Authorization", &self.api_token)
.json(&body)
.send()
.await?;
let resp: graphql_client::Response<create_pub_story::ResponseData> = resp.json().await?;
Updating a post can be accomplished with updateStory() mutation. However, hashnode’s API doesn’t seem to provide a way to retrieve a post’s canonical URL, so we can’t use that to locate an existing article like with devto. Instead, I’ll generate a slug from the filename and look for that. That means I’ll have to handle renaming a file, but I figure that’s less likely to happen than changing the title, body, or something else.
Miscellany
To close this out, a few smaller topics that were useful.
Async
Tokio seems to be the de-facto solution for async Rust. Many of the required types like Future are in the standard library, but the futures crate is still pretty useful. In Cargo.toml:
[dependencies]
futures = "0.3"
tokio = { version = "1.5.0", features = ["full"] }
In main.rs:
#[tokio::main]
async fn main() -> Result<()> {
start().await
}
Elsewhere:
let mut futures: Vec<futures::future::LocalBoxFuture<Result<()>>> = vec![];
futures.push(Box::pin(async move {
let devto = devto::DevtoCrossPublish::new(token.clone(), &settings);
devto.publish(post).await
}));
// Do the same for medium and hashnode...
let results = futures::future::join_all(futures).await;
join_all is similar to the join! macro and essentially awaits an iterator of futures.
Error Handling
There’s been several chapters in the Rust error handling story; failure, error-chain, and a few others I’m forgetting. Apparently those are old and busted, anyhow and thiserror are new hotness.
In Cargo.toml:
[dependencies]
anyhow = "1.0"
thiserror = "1.0"
anyhow works with the std::error::Error trait, propogates errors with ?, allows specifying additional context, and has some useful macros:
use anyhow::Context;
fn can_fail() -> anyhow::Result<()> {
this_fails().context("Failed to whatever")?;
also_fails().with_context(|| format!("Check this: {}", important_thing))?;
if whatever {
// anyhow! macro produces a anyhow::Error
return Err(anyhow!("Missing attribute: {}", missing));
} else if other_thing {
// bail! macro is shorthand for above
bail!("Missing attribute: {}", missing);
}
}
From the docs:
(anyhow::)Error works a lot like
Box<dyn std::error::Error>, but with these differences:
- Error requires that the error is Send, Sync, and ‘static.
- Error guarantees that a backtrace is available, even if the underlying error type does not provide one.
- Error is represented as a narrow pointer — exactly one word in size instead of two.
thiserror is complementary by helping create custom error types that impl std::error::Error and impl Display:
#[derive(thiserror::Error, Clone, Debug)]
pub enum Error {
#[error("Bad path, expected {expected}: {found}")]
BadPath {
expected: String,
found: std::path::PathBuf,
},
//...
}
fn function() -> anyhow::Result<()> {
option.ok_or(Error::BadPath { expected: "...".to_owned(), found: "...".to_owned() })?;
}
It has several other features, check the docs for more information.
If you get this error:
error[E0308]: mismatched types
--> src/platforms/hashnode.rs:148:13
|
148 | Err(Error::NotFound)
| ^^^^^^^^^^^^^^^^ expected struct `anyhow::Error`, found enum `Error`
Use impl From:
Err(Error::NotFound.into())
Logging
I’d wager most people are familiar with log and a logger implementation like env_logger:
use log::{info, trace, warn};
env_logger::init();
info!("Information: {}", value);
tracing is similar. In Cargo.toml:
[dependencies]
tracing = "0.1"
tracing-subscriber = "0.2"
use tracing::{debug, error, info, trace, warn};
tracing_subscriber::fmt().init();
You can use RUST_LOG to filter output:
# PowerShell
$env:RUST_LOG="warn,cargo_bullhorn=trace"
# bash-like
export RUST_LOG=warn,cargo_bullhorn=trace
Tracing provides additional features: logging sections of code with RAII spans, decorator for functions, and more. Check the docs.