In an earlier post we were looking at the performance of function pointers introduced in .NET 5/C# 9.0. To do that we used BenchmarkDotNet (docs), the de-facto .NET benchmarking framework. This is a shotgun dump of notes to get you writing your own benchmarks- mainly for performance regression testing.
Basics
# Install benchmark template
dotnet new -i BenchmarkDotNet.Templates
# Create new benchmark project `benchmarks`
dotnet new benchmark -o benchmarks --console-app -v 0.12.1
Confusingly, you’ll find references to installing BenchmarkDotNet.Tool global tool which has been deprecated (see issue 1670 and PR 1572). Likewise, the dotnet project template BenchmarkDotNet.Templates defaults to: NET Core App 3.0 (which is out of support), and version 0.12.0 of BenchmarkDotNet (which doesn’t support NET 5.0 and may fail with System.NotSupportedException: Unknown .NET Runtime). Open benchmarks/benchmarks.csproj and replace:
-<TargetFramework>netcoreapp3.0</TargetFramework>
+<TargetFramework>net5.0</TargetFramework>
The template is pretty simple, so it’s just as easy to run dotnet new classlib -o benchmarks and populate benchmarks.csproj with:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net5.0</TargetFramework>
<OutputType>Exe</OutputType>
</PropertyGroup>
<PropertyGroup>
<PlatformTarget>AnyCPU</PlatformTarget>
<DebugType>portable</DebugType>
<DebugSymbols>true</DebugSymbols>
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
<Optimize>true</Optimize>
<Configuration>Release</Configuration>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="BenchmarkDotNet" Version="0.12.1" />
<PackageReference Include="BenchmarkDotNet.Diagnostics.Windows" Version="0.12.1" Condition="'$(OS)' == 'Windows_NT'" />
</ItemGroup>
</Project>
In benchmarks/Program.cs, replace the main body with the following to get the same functionality as the benchmark runner CLI (from the docs):
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Running;
namespace benchmarks
{
class Program
{
static void Main(string[] args) =>
BenchmarkSwitcher.FromAssembly(typeof(Program).Assembly).Run(args);
}
}
Create a benchmark in Benchmarks.cs:
using BenchmarkDotNet;
using BenchmarkDotNet.Attributes;
namespace benchmarks
{
public class Delegate
{
[Benchmark]
public void CallDelegate()
{
// Do nothing for now
}
}
}
Try running the benchmarks:
dotnet run --project ./Benchmarks/benchmarks.csproj -- --filter "benchmarks.*"
If you leave off --filter it will wait for input from stdin.
To see the list of CLI options:
dotnet run --project ./Benchmarks/benchmarks.csproj -- -h
More
Invariably, you’re testing some other library as opposed to writing stand-alone benchmarks. And then at some point it may fail with Assembly XXX which defines benchmarks references non-optimized YYY. Everything needs to be compiled for release:
# Add a project reference to assembly we're benchmarking
dotnet add benchmarks reference ./nng.NET.Shared/nng.NET.Shared.csproj
# Note --configuration
dotnet run --project ./Benchmarks/benchmarks.csproj --configuration release -- --filter "benchmarks.*"
Similar to other testing frameworks, you can have initialization and cleanup (that is excluded from benchmark timings) with [GlobalSetup]/[GlobalCleanup] and [IterationSetup]/[IterationCleanup] for per-class and per-iteration behavior, respectively (docs):
public class Delegate
{
delegate int nng_aio_set_output_delegate(nng_aio aio, int index, IntPtr arg);
nng_aio_set_output_delegate nng_aio_set_output;
[GlobalSetup]
public void GlobalSetup()
{
var handle = DllImport.Load();
var ptr = NativeLibrary.GetExport(handle, "nng_aio_set_output");
nng_aio_set_output = Marshal.GetDelegateForFunctionPointer<nng_aio_set_output_delegate>(ptr);
}
[Benchmark]
public void CallDelegate()
{
var _ = nng_aio_set_output(nng_aio.Null, 9, IntPtr.Zero);
}
}
There are two main approaches to defining benchmarks:
- Configs (in either fluent or object style)
- Class/function attributes
Which allows you to configure all sorts of interesting things: benchmark parameters, runtime jobs (e.g. .NET version, JIT/GC), etc.
If you’ve got multiple classes the CLI results are spread out. To get a single, tidy table at the end:
var config = ManualConfig.Create(DefaultConfig.Instance)
.WithOptions(ConfigOptions.JoinSummary);
BenchmarkSwitcher.FromAssembly(typeof(Program).Assembly).Run(args, config);
ManualConfig has numerous more options. Everything in ConfigOptions can be specified as CLI arguments after --. For example, JoinSummary corresponds to --join. Reference -- -h for others.
To quickly iterate at the expense of accuracy use: --job Dry, --runOncePerIteration, or some combination of --warmupCount 1 --iterationCount 1 --invocationCount 1 --unrollFactor 1.
Reports
By default, csv, html, and markdown results are written to BenchmarkDotNet.Artifacts/results/. Other formats are possible with -e, and the base output path can be specified with -a/--artifacts. The markdown is suitable for posts such as this, CI web interfaces, etc.:
BenchmarkDotNet=v0.12.1, OS=macOS 11.3.1 (20E241) [Darwin 20.4.0]
Intel Core i5-8279U CPU 2.40GHz (Coffee Lake), 1 CPU, 8 logical and 4 physical cores
.NET Core SDK=5.0.101
[Host] : .NET Core 5.0.1 (CoreCLR 5.0.120.57516, CoreFX 5.0.120.57516), X64 RyuJIT
DefaultJob : .NET Core 5.0.1 (CoreCLR 5.0.120.57516, CoreFX 5.0.120.57516), X64 RyuJIT
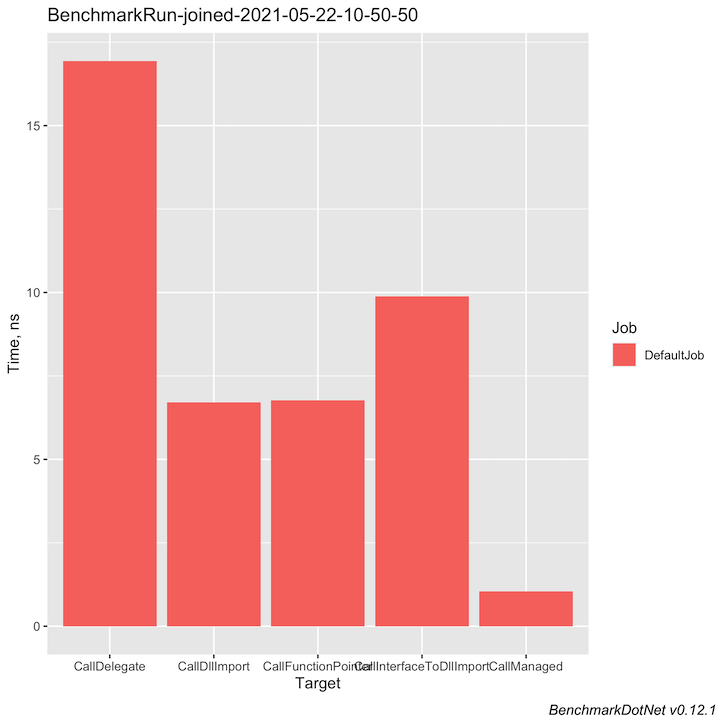
| Type | Method | Mean | Error | StdDev | Ratio | RatioSD |
|---|---|---|---|---|---|---|
| Delegate | CallDelegate | 16.934 ns | 0.1687 ns | 0.1578 ns | 16.23 | 0.23 |
| DllImport | CallDllImport | 6.713 ns | 0.0666 ns | 0.0590 ns | 6.44 | 0.09 |
| Interface | CallInterfaceToDllImport | 9.884 ns | 0.1892 ns | 0.2652 ns | 9.55 | 0.35 |
| Pointer | CallFunctionPointer | 6.764 ns | 0.1519 ns | 0.1347 ns | 6.49 | 0.18 |
| DllImport | CallManaged | 1.042 ns | 0.0125 ns | 0.0110 ns | 1.00 | 0.00 |
To get graphs, install the R programming language and use -e rplot. If rscript is in your PATH environment variable, it will automatically output several png files, otherwise you can manually run rscript BenchmarkDotNet.Artifacts/results/BuildPlots.R:
Comparisons
What’s “fast” (or “slow”)? Benchmarks are sometimes useless without something to compare them to.
You can define a baseline:
[Benchmark(Baseline = true)]
public void CallManaged()
{
var _ = Managed(IntPtr.Zero, 9, IntPtr.Zero);
}
// Prevent inline-ing
[MethodImpl(MethodImplOptions.NoInlining)]
static nint Managed(nint _unused0, int _unused1, nint _unused2) => 0;
Having a baseline also gives you “ratio” and “ratioSD” (StdDev) columns in the output.
BenchmarkDotnet doesn’t natively support comparing results from different runs (i.e. before and after code changes), but you can use ResultsComparer from the .NET project:
# Clone repo and build ResultsComparer
git clone https://github.com/dotnet/performance dotnet_perf
pushd dotnet_perf/src/tools/ResultsComparer
dotnet build -c release
popd
# View CLI options
dotnet ./dotnet_perf/artifacts/bin/ResultsComparer/Release/net5.0/ResultsComparer.dll -h
# Run benchmarks with full JSON reports
dotnet run --project ./Benchmarks/benchmarks.csproj -c release -- -f "benchmarks.*" -e fulljson
# Compare with results in ./base
dotnet ./dotnet_perf/artifacts/bin/ResultsComparer/Release/net5.0/ResultsComparer.dll --base ./base --diff ./BenchmarkDotNet.Artifacts --threshold '5%'
ResultsComparer requires “full” JSON reports. So, you’ll have to do one of:
- Run with
-e fulljson - Call
AddExporter(BenchmarkDotNet.Exporters.Json.JsonExporter.Full)on a config - Apply
[BenchmarkDotNet.Attributes.JsonExporterAttribute.Full]attribute
--threshold sets the permitted variation between results. It can be a percentage, or length of time like 1ms.
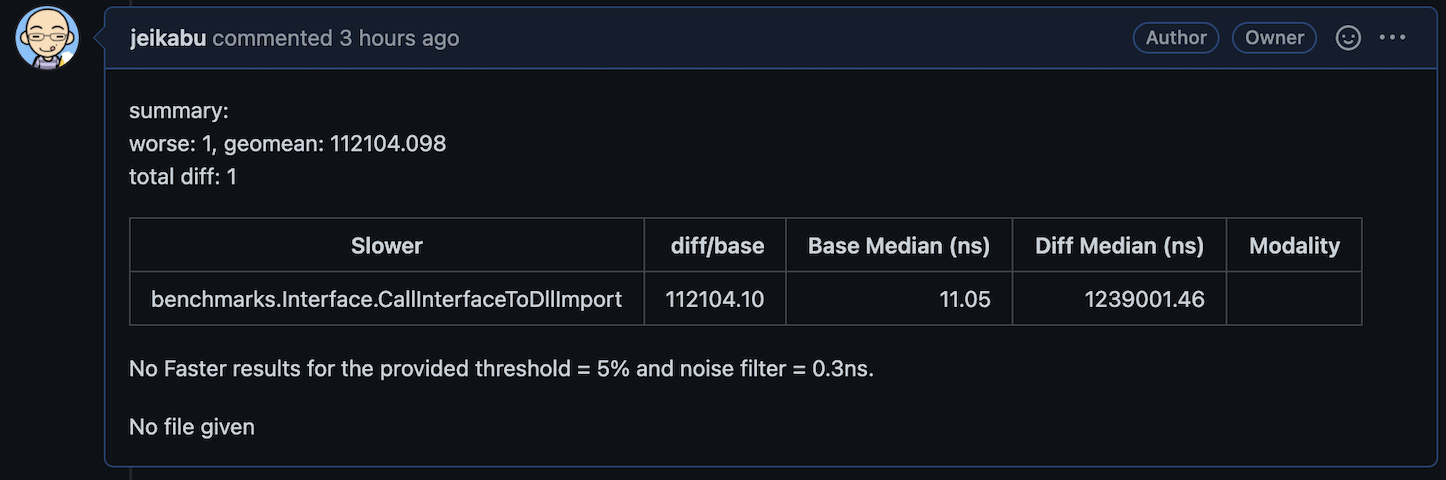
Stdout contains markdown results:
| Slower | diff/base | Base Median (ns) | Diff Median (ns) | Modality |
|---|---|---|---|---|
| benchmarks.Interface.CallInterfaceToDllImport | 112104.10 | 11.05 | 1239001.46 |
Oops, looks like my Thread.Sleep(1) had a measureable impact.
ResultsComparer has some unexpected behavior. It throws an exception when there’s multiple reports in the same folder, so you may need to clear results from repeated runs. And it doesn’t work with results from “dry” jobs.
CI
We’re looking to add this as part of our Github Action workflows, but it applies equally well to any other CI/CD platform.
It’s tempting to fail a build/PR if any benchmark is slower. But, sometimes it’s unavoidable with a bug fix or “correct” implementation. IF we wanted to do it anyway, check if any test is “Slower”:
# Output comparison as CSV `./csv`
dotnet ResultsComparer.dll --base ./base --diff ./BenchmarkDotNet.Artifacts --threshold '5%' --csv ./csv
# Parse csv, give it a header (it doesn't have one), and get 3rd column
$column = Import-csv -Path ./csv -Delimiter ';' -Header 'Benchmark','Source','Result' `
| Select-Object 'Result'
# Check for "Slower"
($column | % { $_.Result }).Contains("Slower")
What we’d really like is a summary in the comments of a pull request- similar to our code coverage reports. There’s multiple ways to add a comment from a workflow:
- github-script block
- curl/REST
- Community marketplace action (option1, option2)
Using HTTP REST, PowerShell works on all platforms and requires no external dependencies:
# Run ResultsComparer and capture markdown output
$output = dotnet ResultsComparer.dll --base ./BenchmarkDotNet.Artifacts/ --diff ./diff --threshold '5%'
# Convert string[] output to single string with line-breaks
$body = $output -join '`n'
$secure_token = ConvertTo-SecureString -String $GITHUB_TOKEN -AsPlainText
# POST comment to PR
Invoke-WebRequest `
-Method Post `
-Headers @{accept= 'application/vnd.github.v3+json'} `
-Uri https://api.github.com/repos/$USER/$REPO/issues/$PR_ID/comments `
-Body (ConvertTo-Json @{body=$body}) `
-Authentication OAuth -Token $secure_token
Where $PR_ID can be obtained from $ in the workflow.
Assuming everything is correct:
We’ve now got a bunch pieces, but haven’t really settled on how we want the process to work. Similar to before, we can attach any of the generated reports with upload-artifact/download-artifact or upload-release-asset as build artifacts or release assets, respectively. And then generate comparison reports. But, it feels best to use a wide gamut of fine-grained benchmarks to catch performance regressions in PRs, and then a smaller number of broader, generalized tests to highlight changes between releases. This calls for more experimentation.